Tag, you're it! A guide on data classification and tagging for data teams

After the recent high-profile data breaches in Australia in the last few years, the general public has very little trust in how organisations handle and safeguard their data. A recent study by the UNSW and the Consumer Policy Research Centre found that 70% of Australians don’t feel in control of their data. Understandably so. Businesses are collecting more data than ever before, but many don’t know how to use and protect this data effectively.
It’s a simple equation. The more data you have, the higher your exposure to breaches, security risks and data mismanagement. And the more you need to do to locate, classify and secure it. As data engineering professionals, we play a critical role in this process.
Being the ‘Marie Kondo’ of data
In this article, I’ll cover some data classification and tagging best practices for data teams. We should be the data Marie Kondos of our organisations, making sure we know what data we have, where everything is stored and how to identify it.
By having teams think upfront about the nature of their data, it can encourage a more strategic and proactive mindset around data management. Otherwise we run the risk of our data lakes turning into data swamps.
And just like how our decluttering guru gets rid of things that don’t spark joy – if data isn’t properly tagged, it really shouldn’t be there!

Data classification
What is data classification?
Data classification is the process of categorising data based on its level of sensitivity and importance, and any regulatory requirements. It provides a structured framework for understanding what data exists, where it resides, and how it should be handled.
Why is data classification so important?
Data classification is a must for the following reasons.

- Security: Properly classifying data allows for the right level of security controls to be applied depending on how important and sensitive the data is to the business. Sensitive information needs to be appropriately masked and only accessed by authorised users.
- Compliance: Legal and industry requirements around data compliance are becoming more stringent. At the minimum, Australian businesses have to comply with data protection laws in Australia such as the Federal Privacy Act and any state-specific legislation. Depending on your global operational footprint and nature of your data, you may have to comply with other standards, such as the GDPR in the EU and the California Consumer Privacy Act (CCPA) and Health Insurance Portability and Accountability Act(HIPAA) in the USA.
- Efficiency: Knowing what data you have helps your business to be more efficient. For example, with data tags, development teams can track changes on different environments (prod, test, dev). Operational data can be analysed for insights to optimise processes. Operations teams can search through data easily and use it for monitoring and detecting anomalies, minimising time lost to outages.
- Cost control: Understanding and classifying your data has cost advantages too. The most sensitive data needs additional protocols and encryption which will cost more. This level of security wouldn’t be needed for public or less sensitive data. Understanding how long data needs to be retained can help your business make strategic decisions around how to tier your data storage to reduce redundancy and save costs.
How should data be classified?
The following questions are a helpful starting point for the data team to ask at the start of any project, or when doing an audit of an organisation’s overall data strategy.
- Source: What are the APIs, applications, databases, etc. that data is coming from?
- Sensitivity: How sensitive is the data – what would be the impact to the business if this data was exposed? Do any compliance standards apply to how this data is handled? Who is allowed to access this data?
- Availability: How available does the data need to be? Does it need to be retrieved instantly or is it archival data that isn’t time-critical?
- Retention: How long must the data be retained? Generally, businesses should not hold onto data longer than they need to.
At the very minimum, all organisations, no matter the size of the business, should apply three levels of data classification.
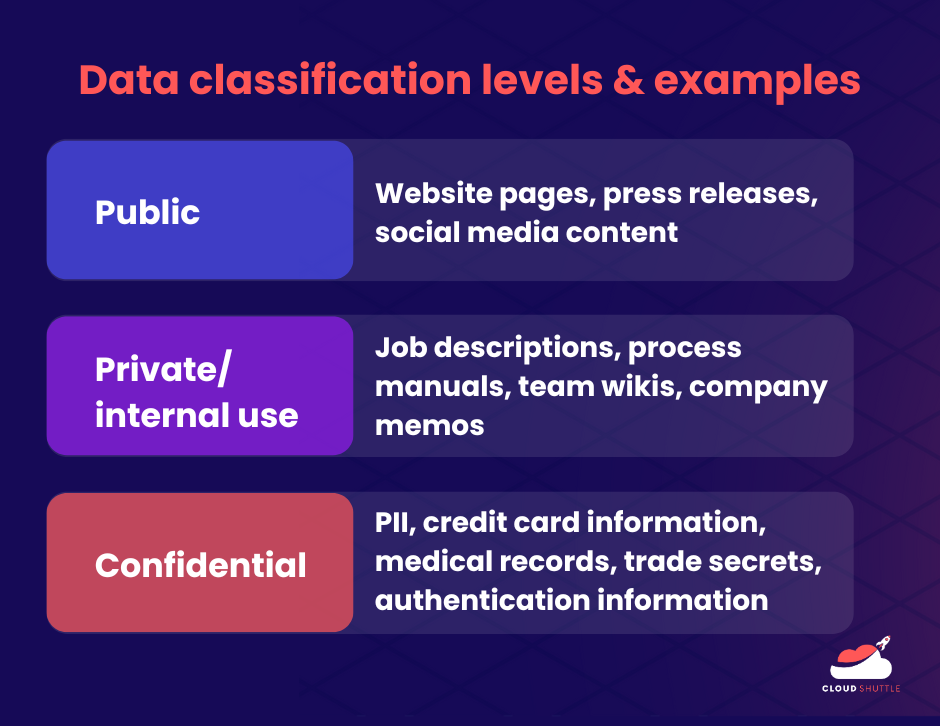
- Public: This refers to any information that is freely and publicly available, such as public website pages, press releases, and social media assets on company channels.
- Private/internal use only: Any information that should be for internal use only, and also does not contain any restricted data. For example, internal company documents, team wikis, process manuals, company-wide emails and memos.
- Confidential: Highly sensitive information such as financial information, credit card information; Personally Identifiable Information (PII) such as medical records, driver’s licence numbers and home addresses; or protected IP such as trade secrets. This also includes data used for authentication, such as encryption keys, hash tables, and so on.
The data in level 3 has additional security and compliance requirements beyond the data in the first two levels. If data falls into two or more categories (for example, company financial statements), it’s best to err on the side of placing it in the higher category.
Data tagging
What are data tags?
Data tags are metadata labels that add context and meaning to your data. In short, data about data.
They take the form of key-value pairs, which consists of two elements: a key, which is constant and applies to a data set (e.g. location, age, department) and a variable value that belongs to that data set (e.g. Australia, >30 years old, Marketing).
What data tags should my team apply?
Of course, every organisation will have unique tagging requirements based on their business logic, but for general data management, my recommendation is that data teams should apply the following tags at the very minimum:
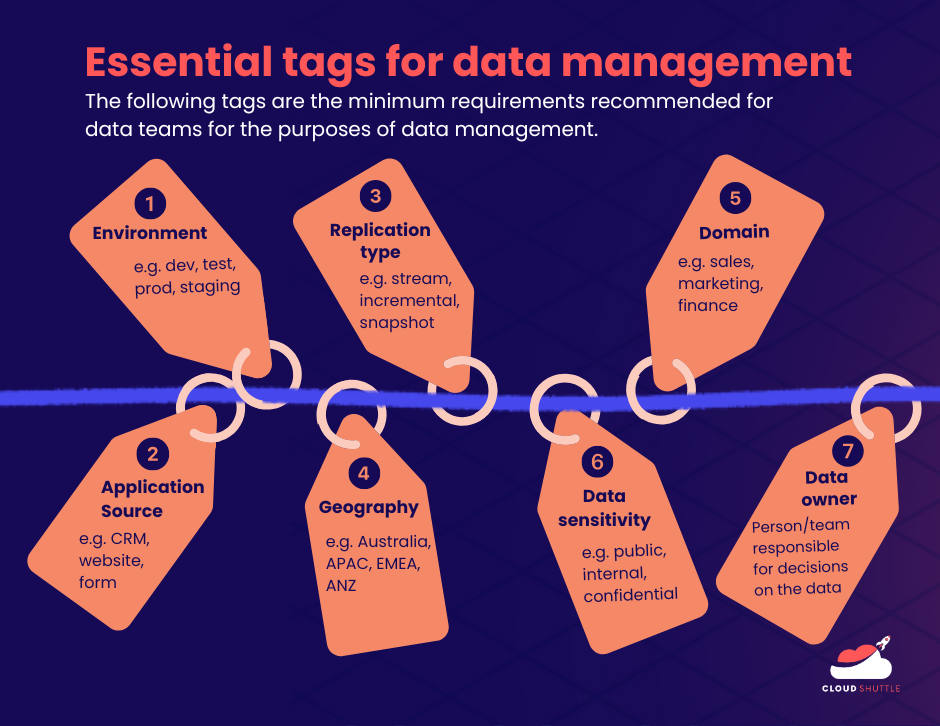
- Environment: e.g. dev, test, staging, production
- Application source: e.g. CRM, web application, website form, etc.
- Replication type: stream, incremental, snapshot
- Geography: e.g. Australia, APAC, ANZ, EMEA, etc. (as mentioned before, your data management processes must be compliant with the regulations of the region you have a footprint in)
- Domain: e.g. product, sales, marketing, finance
- Data sensitivity: e.g. Public, internal, confidential
- Data owner: the team/individuals responsible for decisions on the data.
Best practices for data tagging
OK, so now that we know the importance of classifying data, how do we go about implementing an effective data strategy? This requires collaboration with various departments across the business and a consistent approach.
I recommend the following steps:
- Collaborate with stakeholders: In addition to the tags I’ve recommended above, engage with business stakeholders to understand their use cases, as this will inform additional tagging requirements.
- Define a tagging framework and governance: Establish what tags are mandatory and which ones are optional. Work on standardising naming conventions and how to reconcile variables (e.g. in spelling, abbreviation, capitalisation and variations in how teams understand and apply terms). Create guidance around deleting or creating new tags and how to enforce tagging.
- Implement tagging: Apply tags to all incoming data consistently so the data is relevant and accurate.
- Improve and iterate on tagging strategy: Build in periodic checks (e.g. annually or every 6 months) to review and refine your tagging strategy based on feedback or business needs. As the business evolves, so should your tagging strategy.
Example: Data tagging in action
Let's illustrate the concept of data tagging with a practical example using Snowflake.
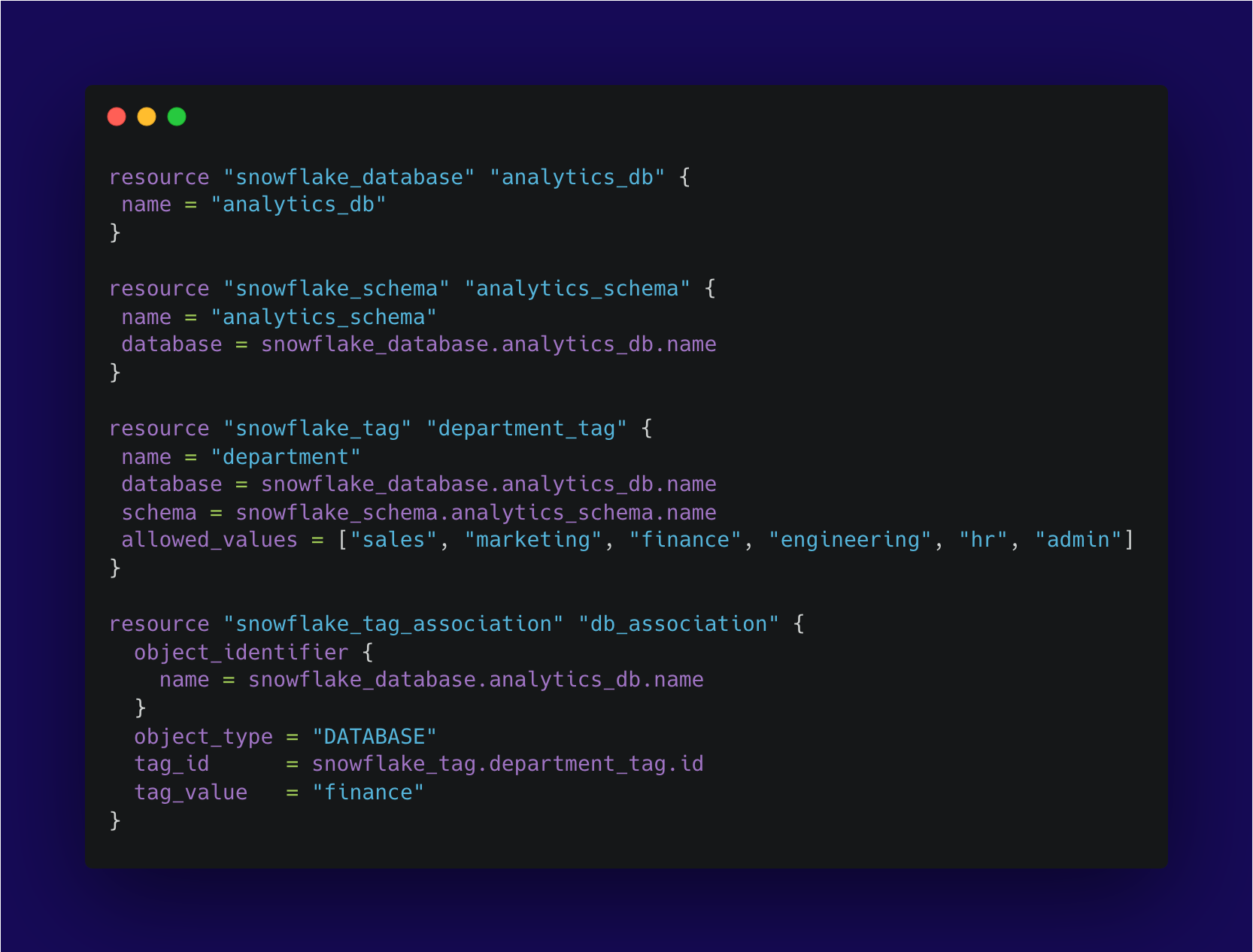
In the example above, we first define a Snowflake database resource named "analytics_db", representing a database where analytical data is stored. This database will serve as the foundation for our data tagging operations.
Next, we define a Snowflake schema resource named "analytics_schema" associated with the "analytics_db" database. This schema represents a logical grouping of tables and objects within the database, providing a structured environment for our data.
Finally, we define a Snowflake tag resource named "department_tag" with the name "department". We specify that this tag is associated with the "analytics_db" database and the "analytics_schema" schema. We define the allowed values for this tag, which are "sales", "marketing", “finance”, “engineering”, “hr” and “admin”. Any data tagged with the "department" tag must draw from these values. We then associate the tag ID with the particular object, which in this case is the database.
Conclusion
Just as Marie Kondo transforms chaotic spaces into calm sanctuaries, data professionals can champion best practices in classification and tagging to bring order to our organisations’ data.
Classifying and tagging data is a simple but powerful prerequisite to ensuring that it is accessible, secure, actionable and cost-effective.
By keeping our data watertight we can help our colleagues perform their jobs better and focus on innovating. And in turn, we’ll bring a lot more joy and less stress to our day-to-day lives.
At Cloud Shuttle, we can help you with categorising and tagging your data for optimal accessibility and compliance. Reach out if you want to uplift your team’s data cataloguing capabilities and enable your business to make blazingly fast and informed decisions.
RELATED_NODES
NODE_CHAIN // SIG_FAST
NODE_01
Static egress IPs for Postgres on Fly.io: an Envoy egress proxy
Jun 8, 2026 · 06m read
NODE_02
AI Observability in Action: Cost Measurement & Evals with Bifrost, Langfuse, and Drover
Jun 5, 2026 · 06m read
NODE_03
Self-Governing Codebases: Bridging the Code-Architecture Gap with Governed RLMs
Jun 4, 2026 · 06m read
Cloud Shuttle Insights