Breaking the Schema Barrier: Our Hands-On Experience with TableFlow for Data Contracts

Breaking the Schema Barrier: Our Hands-On Experience with TableFlow for Data Contracts
From our experience working with data teams across fintech, logistics, insurance, and more, we've seen the same pain points show up time and again: managing metadata, tracking schema changes, and maintaining data ownership—especially in event-driven systems—is still a major challenge.
Even with mature stacks, things break. A schema change upstream, a renamed field, a forgotten Kafka topic—suddenly dashboards are blank, alerts are firing, and no one knows who to talk to. It's not just a tech issue—it's about how teams communicate and collaborate.
That's why we started experimenting with TableFlow at Cloud Shuttle. It caught our eye because it addresses these issues without trying to reinvent everything. And while we're still early in the journey, what we're seeing so far is genuinely promising.
Where We Keep Seeing Things Break: Ownership and Evolution
With the variety of clients we work with, we've seen how common it is for data teams to operate with a mix of technologies: traditional RDBMS, batch pipelines, and now increasingly, streaming systems powered by Kafka, Protobuf, and event-driven microservices.
As teams scale, we notice a trend—the connection between producers and consumers weakens. A producer changes a schema, but doesn't communicate it. A consumer silently fails, and the issue gets buried in a backlog of Jira tickets.
And when real-time systems are involved, you don't just need schema documentation—you need versioned history, impact visibility, and clear ownership. Without that, even simple changes can create widespread disruption.
The Schema Evolution Challenge
Schema evolution is particularly challenging in modern data ecosystems for several reasons:
- Decentralized Development: Multiple teams make changes independently
- Velocity of Change: Rapid development cycles make it hard to track changes
- Cross-Team Dependencies: Changes upstream affect downstream systems in ways that aren't always obvious
- Legacy Integration: New systems need to coexist with legacy platforms that may have different governance models
These challenges become even more pronounced in industries like fintech, where data accuracy isn't just about business intelligence—it's about regulatory compliance and financial accuracy.
Our Take on TableFlow
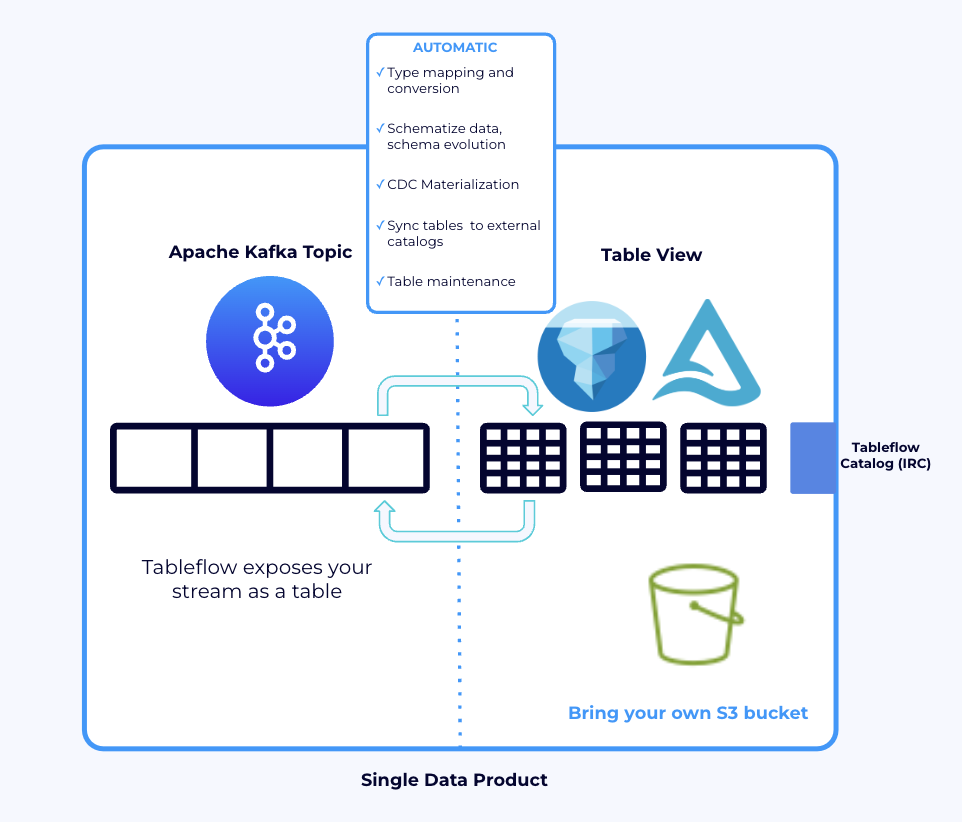 Image courtesy of Confluent, via the: Tableflow is now generally available
Image courtesy of Confluent, via the: Tableflow is now generally available
Our thoughts on TableFlow? It isn't trying to replace your entire governance or data catalog tooling—and that's a good thing. Instead, it's focused and purpose-built: it gives engineers visibility into schema evolution, data contracts, and lineage in ecosystems like Kafka.
We've started using it internally at Cloud Shuttle, connecting it to a sandbox project with Protobuf schemas, Kafka topics, and some light Mage lineage. Even in this early setup, a few things have stood out:
- It's fast to get started with—no heavy configuration needed.
- Schema diffs are visual and easy to track across versions.
- Kafka topic discovery gives you a map of what's flowing through the pipes.
- Contract validation helps catch incompatible changes before deployment.
How We See This Playing Out for Clients
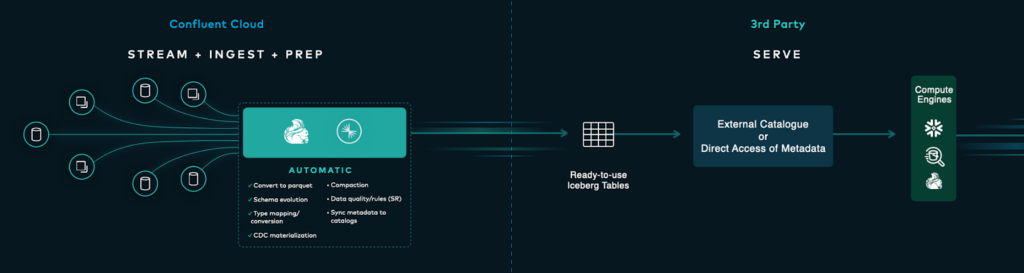 Image courtesy of Confluent, via the: Introducing Tableflow: Unifying Streaming and Analytics
Image courtesy of Confluent, via the: Introducing Tableflow: Unifying Streaming and Analytics
Based on our work across domains, we can already see TableFlow offering real value to:
- Fintech teams, who need to maintain rigorous audit trails and ensure data integrity across fast-moving services.
- Logistics platforms, where tracking data about real-world objects—vehicles, parcels, inventory—requires reliable contracts and well-governed schemas.
- Data platform teams in enterprise environments, looking to standardise governance across dozens of microservices and data producers.
- Healthcare organizations managing sensitive patient data where schema consistency is critical for both operational and compliance reasons.
We're especially keen to explore how TableFlow can be used alongside tools like OpenLineage or Mage for richer lineage, or how it complements schema registries in Kafka-heavy setups.
What Our Engineers Are Saying

Our team is always up for a hands-on trial with new tools—but the ones we keep using are the ones that actually reduce friction and help us build with confidence.
Here's what one of our engineers shared recently:
"TableFlow feels like it was built by people who've actually worked in messy, real-world systems. It's simple but smart. The versioning is clean, and being able to just see what's changed in a Kafka topic without digging through commits or wiki pages—that's powerful."
It's still early days, but feedback like this gets us excited about the direction. We're not just experimenting—we're actively exploring how TableFlow can become a trusted part of our toolkit, and potentially our clients' stacks as well.
Practical Implementation: Our Approach
For teams considering TableFlow, here's how we're approaching implementation:
- Start Small: Begin with a subset of critical topics or schemas
- Connect with CI/CD: Integrate schema validation into your deployment pipelines
- Establish Ownership: Use TableFlow to document and enforce data ownership
- Create Standards: Develop team standards for schema changes and communication
- Measure Impact: Track incidents related to schema changes before and after implementation
This phased approach allows teams to see immediate value while building toward a more comprehensive governance model.
Why We're Paying Attention
We've seen plenty of tools promise visibility and governance, but many of them cater more to data stewards or compliance teams than engineers in the trenches.
What's refreshing about TableFlow is that it doesn't try to be everything. It doesn't replace your data catalog. Instead, it picks a real, specific pain point—and goes deep. For us, that makes it worth investing time in.
At Cloud Shuttle, we're continuing to explore its fit within our internal systems and looking at how it might strengthen data contract practices in client environments. We'll keep sharing what works and what doesn't, and we're always keen to compare notes with other teams navigating similar terrain.
Key Takeaways
- We're actively testing TableFlow internally and finding early value in how it tracks schema changes, contracts, and topic discovery.
- It's not a governance monolith—it's a lightweight, engineer-friendly solution for real-time observability in event-driven systems.
- Industries like fintech, logistics, and large platform teams stand to benefit most from its focused approach.
- Cloud Shuttle is exploring how to integrate it with broader stacks like Mage, OpenLineage, and Kafka schema registries.
Suggested Reads and Resources
- Introducing Tableflow: Unifying Streaming and Analytics
- Tableflow is now generally available
- Data Contracts: What Are They? Why Are They Essential?
- What is Confluent TableFlow?
If you're facing similar challenges with schema management and data contracts, we'd love to hear about your experience. Reach out to us at Cloud Shuttle to discuss how these approaches might benefit your data architecture.
RELATED_NODES
NODE_CHAIN // SIG_FAST
NODE_01
Static egress IPs for Postgres on Fly.io: an Envoy egress proxy
Jun 8, 2026 · 06m read
NODE_02
AI Observability in Action: Cost Measurement & Evals with Bifrost, Langfuse, and Drover
Jun 5, 2026 · 06m read
NODE_03
Self-Governing Codebases: Bridging the Code-Architecture Gap with Governed RLMs
Jun 4, 2026 · 06m read
Cloud Shuttle Insights