Leading a data platform team to DataOps success

It was a watershed moment when Patrick Debois coined the term “DevOps” in 2009, in an attempt to bridge an often adversarial relationship between developers and system admins (watch a video of the fascinating history of DevOps here). Since then, you’ll be hard-pressed to find any high-performing technology team that doesn’t champion DevOps practices in their engineering culture.
Within the data realm, DataOps has gained traction as the data-specific implementation of DevOps. For data managers and engineers, implementing continuous integration and continuous delivery (CI/CD) helps with managing and automating data pipelines in the building, testing and deployment stages. The result is that any data changes are integrated smoothly into production. DataOps is the key to speeding up the journey that raw data takes to become useful business insights.
In this article, I’ve written a basic guide on what’s involved in setting up CI/CD and unit and integration tests for your data pipelines. There’s no better feeling as a data engineer than deploying changes quickly, with no merge conflicts, and with confidence that your code is backed up by good test coverage and will perform well in production.
What is CI/CD with unit and integration testing?
CI/CD is a framework that automates the software release process.
- The 'CI' in CI/CD refers to ‘Continuous Integration’, a practice where developers regularly merge code changes into a central repository, which is then automatically tested.
- 'CD' stands for ‘Continuous Delivery/Deployment’, where the validated code is automatically deployed to a production or testing environment.
Unit and integration testing involves testing individual components (units) or groups of components (integration) to ensure they work as expected.
DataOps vs DevOps
While the core principles of CI/CD are shared between data engineering and software engineering, there are some differences in the way they’re implemented.

Software engineering is focused on building and deploying software applications, fixing bugs and improving product features. Data engineering pipelines deal with different payload types such as data models and datasets. Data engineers need to address specific concerns such as data quality, schema evolution, data modelling and data consistency, which are less of a focus in traditional software engineering workflows.
Let’s illustrate this with the following comparison:
- A software engineer creates a feature branch from the development branch in a version control system (e.g. GitHub). They would then commit the changes, which are validated by unit and integration tests, before pushing the changes to the repo. The CI/CD system will then handle the deployment of the code to both the staging and production environment.
- A data engineer branches off from the main development branch in a version control system like GitHub, making changes to data models or ETL scripts. These changes are committed along with tests to verify the data’s integrity and schema consistency. Once pushed, the CI/CD system automates the data pipeline's deployment, executing data validation and integration tests before moving data through to staging, and eventually, to the production environment. Once in production, it becomes available for analysis and decision-making.
What are the benefits of CI/CD for data projects?
CI/CD pipelines orchestrate the flow of data from source to destination, ensuring that the data is processed, tested, and deployed consistently and reliably. This allows for frequent updates, quick responses to changes, and the delivery of high-quality data solutions.
- Enhanced agility and faster deployment: CI/CD allows data teams to make incremental changes to data processes without risking the overall system stability. Automated testing and deployment phases are in place so that changes made to the data processing logic, data models or data itself are always tested against predefined criteria. You end up with a rapid feedback loop so you can identify and correct errors and reduce the number of issues that need to be fixed after deployment.

- Improved collaboration: The places that I’ve worked at that have implemented CI/CD in their data pipelines have invariably been more pleasant and productive environments. Because processes are repeatable and changes trackable, there’s greater transparency on the data flows within the organisation. This leads to better collaboration between data engineers, data scientists and data analysts and a sense of shared responsibility for the data’s accuracy and timeliness. We end up having fewer complaints and better quality insights for our data consumers.
- Scalable and reliable data pipelines: When businesses grow, so does the amount of data that needs to be handled. The business requirements for the data also evolves over time. CI/CD helps efficiently manage these changes by allowing new data sources and technologies to be integrated in the existing data stack. This means that the business’ data infrastructure can scale up as needed without compromising the quality or availability of data.
How to set up a CI/CD for data projects
Now that we have a better idea of its benefits, here’s my step-by-step guide on how to set up a CI/CD pipeline for your data projects:
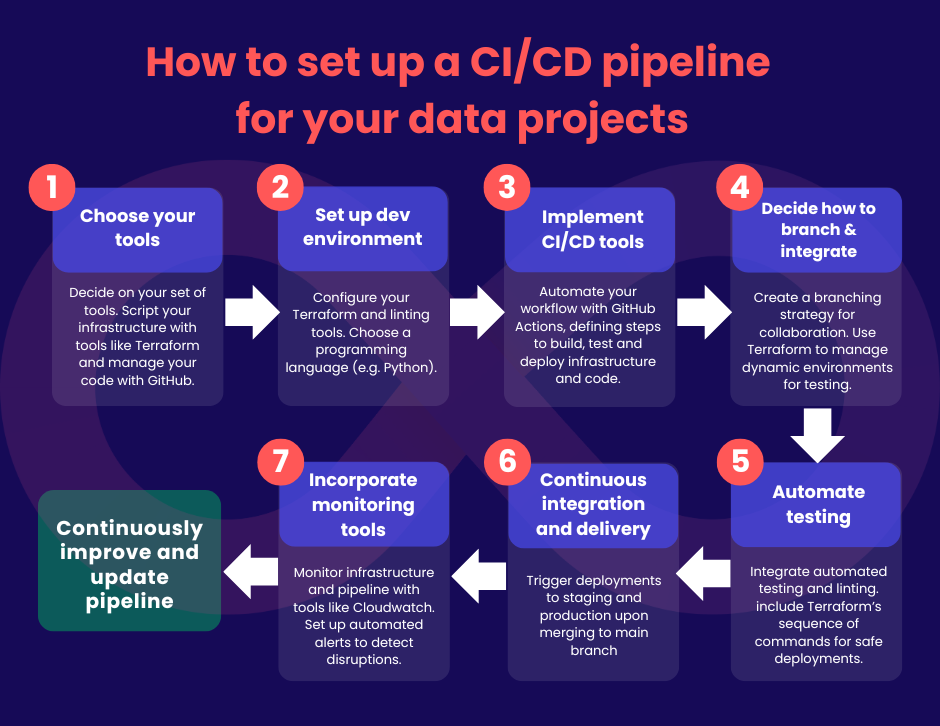
- Choose your tools
- Infrastructure as Code (IaC): Terraform is widely used by data engineers for managing infrastructure. It allows you to script the setup of environments such as EC2 instances, Lambda functions, or Docker containers on Kubernetes or EC2.
- Version control: Use tools like GitHub to manage your codebase and collaborate with your team.
- Set up your development environment: Next, configure your Terraform environment. This will include setting up remote state management and integrating linting tools for checking code errors and enforcing style consistency. You’ll then have to decide on the programming language for your application code. For us data engineers, Python is our usual go to because of its extensive libraries and suitability for data tasks.
- Implement CI/CD tools: Use GitHub Actions to automate your workflows directly from your GitHub repository. You can configure GitHub Actions to handle both infrastructure deployment and application code updates. Define steps that build, test, and deploy both components.
- Develop your branching and integration strategy: Develop a branching strategy that supports multiple developers while maintaining code integrity. Typically, branches are created for specific features or tickets (e.g., ENG-123). Implement ephemeral environments for each branch using dynamic naming conventions, which can be facilitated through Terraform. This allows isolated testing and integration before merging any changes back to the main branch.
- Automate testing, linting and deployment: Automate your testing process to include both unit tests for application logic and integration tests that simulate real-world data operations like batch processing or data upserts. Terraform’s sequence of commands (terraform fmt, terraform init, terraform validate, terraform plan, terraform apply) should be included in your CI/CD pipeline so you can make sure that your infrastructure changes are viable and safe to deploy.
- Continuous integration and delivery: Once code is merged into the main branch after testing, it automatically triggers the deployment process to the staging environment, followed by the production environment. Ensure that all deployments are subject to final checks to confirm that everything is operating as it should in a live setting. Unlike traditional software where testing is often done in the pre-deployment stage, a fair amount of testing may occur post-deployment due to the dynamic nature of data. This is where your data quality checks and validations come in, to ensure the data transformations and integrations meet the required standards.
- Incorporate monitoring tools: Use tools like CloudWatch for AWS or Cloudwatch logs to monitor the health and performance of your infrastructure and data applications. Pay special attention to the performance of data pipelines since they are so crucial. Monitor how long the pipeline takes to execute and be on the alert for any slow creep where pipelines take gradually longer and longer to complete as it could signal deeper problems. Setting up automated alerts when anomalies occur allows your team to be more proactive when there are disruptions.
Don’t forget to regularly review and update the CI/CD pipeline to adapt to new technologies, project requirements, and to look for ways to make the process more efficient.
Conclusion
To succeed in today’s environment, data teams should embrace the DevOps principles that our software engineering brethren have made mainstream. I promise that it’s a game changer. Taking a similar agile approach helps us deliver more value, more quickly to our data consumers. By integrating continuous integration and delivery, we can deploy more frequent updates, adapt to changes and deliver more robust data solutions. We’ll help our colleagues and businesses to leverage data assets a lot more effectively and with much greater confidence.
At Cloud Shuttle, we walk the talk. All our engagements involve establishing a robust CI/CD pipeline for your data projects. And we’ll help uplift your team’s DataOps practices so your business can benefit from increased agility, reliability and superior data quality. Connect with us today!
RELATED_NODES
NODE_CHAIN // SIG_FAST
NODE_01
Static egress IPs for Postgres on Fly.io: an Envoy egress proxy
Jun 8, 2026 · 06m read
NODE_02
AI Observability in Action: Cost Measurement & Evals with Bifrost, Langfuse, and Drover
Jun 5, 2026 · 06m read
NODE_03
Self-Governing Codebases: Bridging the Code-Architecture Gap with Governed RLMs
Jun 4, 2026 · 06m read
Cloud Shuttle Insights