What We Learned at Confluent's DSWT Sydney: Real Streaming Stories That Matter

Last week, the Cloud Shuttle team joined hundreds of data professionals at Confluent's Data Streaming World Tour 2025 – Sydney, a key stop in a global series focused on the future of real-time data. While the term "streaming data" often gets tossed around in buzzword-heavy conversations, this event cut through the noise with deeply practical insights - especially for those of us helping businesses scale modern data platforms.

From financial services and agriculture to government and banking, Australian and New Zealand organisations are going beyond batch processing and rethinking how data flows across systems. This blog distills the most valuable lessons we took away from the event - covering the shift from batch to real-time, case studies from ASX, Bendigo Bank and LIC, deep dives into TableFlow and Apache Iceberg, and what all of this means for your own data architecture, costs, and future planning.
Whether you're an enterprise with legacy systems, a scale-up navigating growing data demands, or a startup building on cloud-native foundations, you'll find tangible takeaways here to inform your next data move.
From Batch to Real-Time: A New Era for Data Infrastructure

The keynote from Tim Berglund, VP of Developer Relations at Confluent, set the tone for the day. He mapped out the evolution of data processing over three decades:
-
1990s: Data warehouses brought structure and batch analytics, but introduced latency.
-
2010s: Kafka emerged, enabling event-driven systems and the rise of the stream processor.
-
2020s: We're now integrating AI and machine learning directly into streaming pipelines, enabling smarter, real-time decision-making at scale.
One standout metaphor: Tim described event streaming as the "central nervous system" of a business - a core layer that connects everything else, transmitting signals in real-time. Contrast that with traditional point-to-point integration models, which often result in brittle, tangled webs of dependencies.
At Cloud Shuttle, we see this evolution firsthand. One of our retail clients shifted from overnight batch loads to real-time Kafka-based streaming and saw latency drop from hours to seconds, dramatically improving stock-level visibility and enabling real-time decision-making.
Key takeaway: If you're still stuck in a batch ETL mindset, you're not just dealing with slower data - you're limiting how your business can respond to change.
Case Studies That Hit Home
Here are three standout case studies from the event that showcase what's possible when you commit to streaming-first thinking.
1. ASX: Streaming the Financial Markets
Speaker: Sumit Pandey, ASX
The ASX operates under some of the most demanding conditions in the country: ultra-low latency, rock-solid reliability, and non-negotiable compliance standards.
Their team deployed Confluent across a hybrid architecture - linking on-prem Kafka clusters with cloud-native infrastructure - and implemented:
- Tiered storage: Hot data on EBS, cold archival on S3
- Intelligent partitioning: Based on trade volumes and patterns
- Guaranteed delivery: For market-critical transactions
Outcome: They reduced market data latency from seconds to milliseconds, while dramatically simplifying compliance workflows.
Cloud Shuttle Insight: We see strong potential for financial services clients with hybrid environments to adopt similar architectures - especially by combining tiered storage, schema governance, and real-time pipelines. These design choices help reduce latency, improve observability, and simplify regulatory reporting.
2. Bendigo Bank: Accountability and Cost Transparency
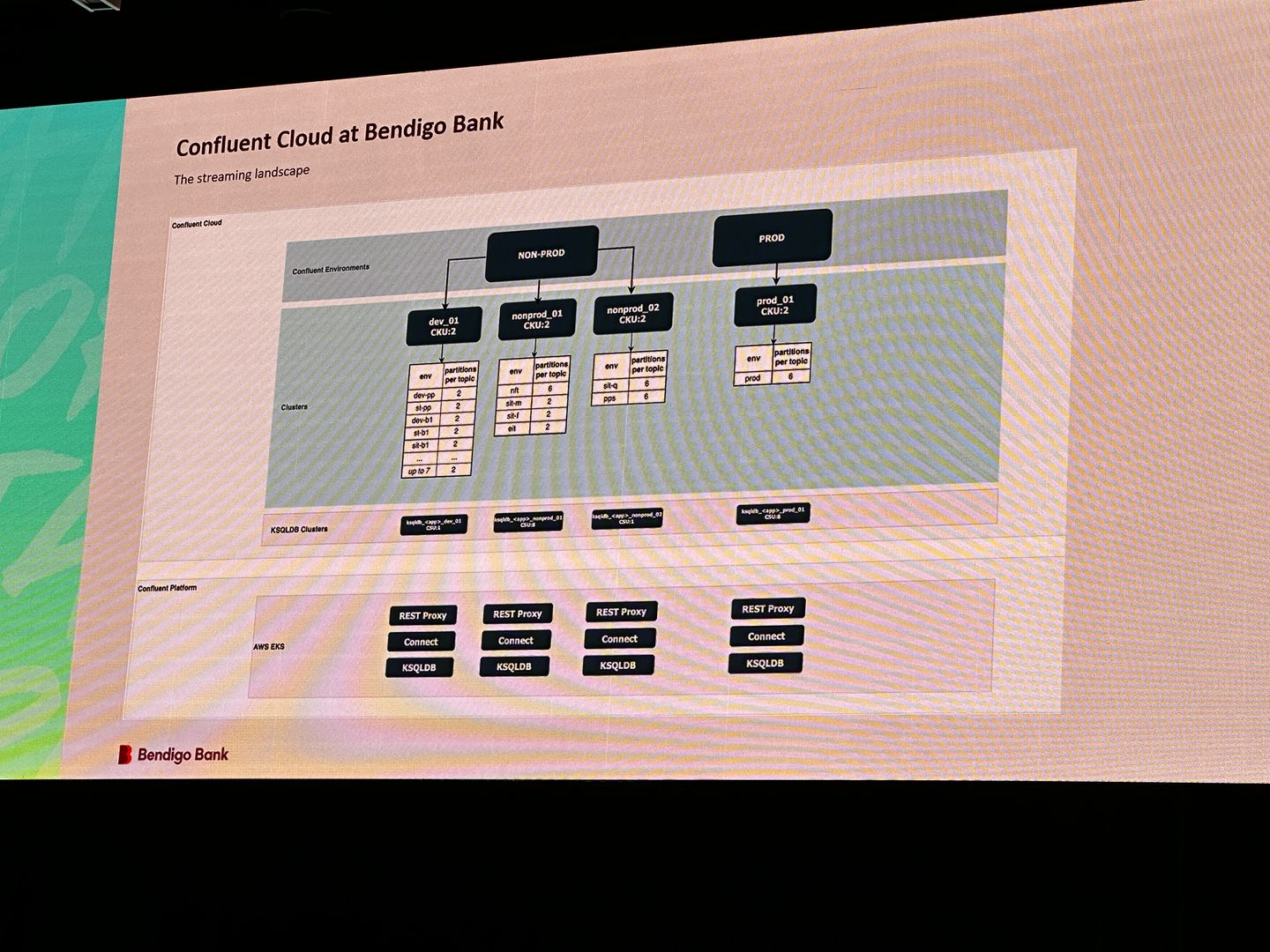
Speaker: Dom Reilly, Bendigo Bank
Bendigo Bank had a complex hybrid Kafka footprint spanning Kubernetes, AWS, and Confluent Cloud - but as usage scaled, so did challenges: rising costs, storage sprawl, and unclear ownership.
Their strategy included:
- Cost attribution dashboards using Confluent APIs
- A chargeback model to make usage visible at the team level
- Cleanup efforts targeting orphaned topics and inefficient retention settings
Cloud Shuttle Insight: As more organisations adopt streaming at scale, we believe cost transparency will become a key architectural concern. By using team-level visibility, chargeback models, and lifecycle enforcement, companies can optimise both spend and platform health - especially relevant for mid-size banks and fast-scaling enterprises.
3. Livestock Improvement Corporation (LIC): Streaming for Sustainability
Speaker: Vik Mohan, LIC (New Zealand)
LIC's work stood out as one of the most creative and high-impact use cases of the event. They're reshaping modern dairy farming through streaming-powered insights:
- IoT + biometric sensors to monitor animal health
- Real-time correlation of GPS, weather, and performance data
- Streaming alerts to optimise breeding windows and detect illness early
Results:
- 15% increase in milk production
- 22% reduction in animal health issues
Cloud Shuttle Insight: For clients in agriculture, manufacturing, and sustainability sectors, this showcases what's possible when IoT meets streaming. There's clear potential to unlock operational gains through real-time alerting, predictive analytics, and automated interventions - even in traditionally non-digital industries.
Deep Dives: TableFlow, Flink SQL, and Apache Iceberg
Beyond the case studies, a few technical sessions really stood out for the engineering crowd.
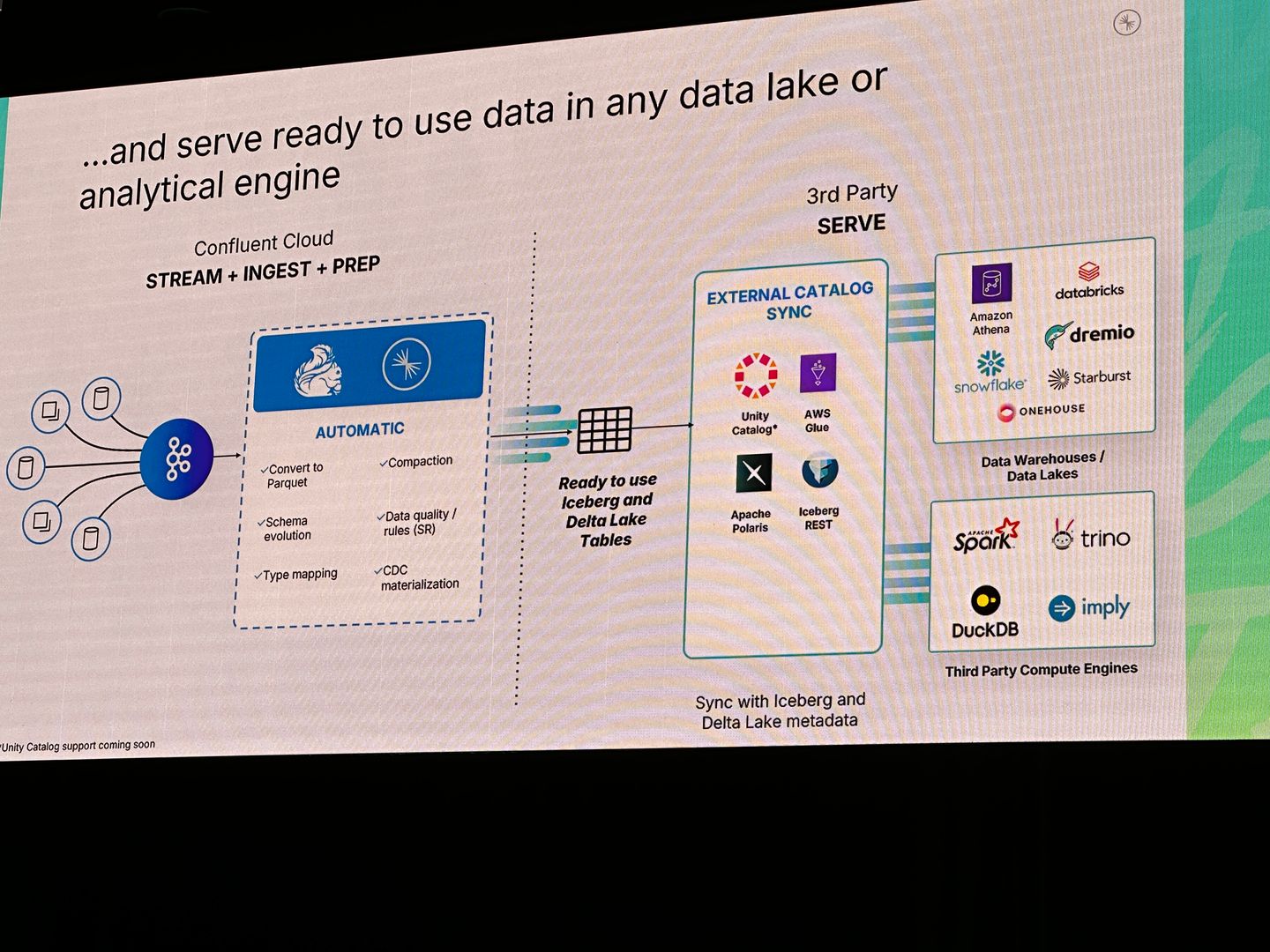
TableFlow + Flink SQL: Real-Time Analytics Without ETL Pain
Speaker: Prerna Tiwari, Confluent
TableFlow lets you expose Kafka topics as tabular, queryable structures, eliminating the need for costly batch pipelines or intermediate storage layers - a major win for teams aiming to simplify their streaming architecture.
Problems it helps solve:
- Data duplication across staging layers
- Compute waste from repeated batch jobs
- "Small file" issues common in cloud object storage
It pairs particularly well with Flink SQL, enabling real-time data enrichment and complex joins — all without materialising data in a downstream warehouse.
Cloud Shuttle Insight: From what we saw, Flink SQL + TableFlow will empower teams to deliver OLAP-style analytics directly from streaming data - making it a strong fit for operations dashboards, real-time marketing triggers, and anomaly detection pipelines. For data-rich startups and enterprises alike, this could remove major friction in building time-sensitive analytics.

Apache Iceberg: A Modern Layer for Streaming and Lakehouse Storage
Iceberg came up repeatedly during the event, and for good reason. It brings proper governance, atomic transactions, and time-travel querying to cloud-native data lakes, solving many of the pain points associated with traditional big data architectures.
Key Benefits:
- Version control for data - easily roll back bad loads
- Schema evolution - adapt without breaking downstream consumers
- Seamless integration with Kafka and Flink for real-time ingestion
Cloud Shuttle Insight: For organisations currently using Hive-based or Presto-backed data lakes - especially those struggling with schema drift, lack of rollback, or costly reprocessing - Iceberg offers a compelling path forward. We see strong potential for clients looking to unify real-time pipelines and analytical workloads on a single foundation, while also improving governance and reducing complexity.
What This Means for Your Data Strategy
Streaming is no longer experimental - it's quickly becoming core to modern data stacks.
From the sessions and case studies at DSWT Sydney 2025, a few patterns stood out:
-
Real-time pipelines are replacing batch
Tools like Flink SQL and TableFlow let you work with live data directly – no need for brittle ETL chains. -
Modern lakehouses are operational and governed
Apache Iceberg brings version control, schema evolution, and reliability to cloud object storage. -
Cost and governance matter more than ever
As streaming scales, teams need better visibility and accountability around platform usage. -
Hybrid cloud is the new normal
Many teams are blending on-prem and cloud, and modern tools are built to support both.
Teams dealing with large volumes of fast-moving data – especially in finance, SaaS, and IoT – are already leaning into these shifts. It's not about rearchitecting everything overnight, but knowing where to start.
Where Cloud Shuttle Fits In
At Cloud Shuttle, we help data-heavy teams figure out:
- Where streaming fits in their current stack
- How to use Iceberg without breaking existing tools
- Ways to surface insights in real time - without warehouse sprawl
- How to track costs and keep teams accountable as platforms scale
If you're wrangling messy pipelines, rising infra bills, or delayed insights, we're here to help cut through the complexity.
Wrapping Up
Confluent's DSWT Sydney made one thing clear: the gap between batch and real-time is closing fast, and the winners will be those who design for streaming from day one. Whether you're navigating Kafka sprawl, exploring Iceberg, or just trying to make sense of the tooling shift—there's never been a better time to rethink your data architecture.
If any of these ideas sparked something, let's unpack it properly. Book a time for a quick chat. No pitch-just practical thinking.
RELATED_NODES
NODE_CHAIN // SIG_FAST
NODE_01
Static egress IPs for Postgres on Fly.io: an Envoy egress proxy
Jun 8, 2026 · 06m read
NODE_02
AI Observability in Action: Cost Measurement & Evals with Bifrost, Langfuse, and Drover
Jun 5, 2026 · 06m read
NODE_03
Self-Governing Codebases: Bridging the Code-Architecture Gap with Governed RLMs
Jun 4, 2026 · 06m read
Cloud Shuttle Insights