Why Data Products are the Future of Data Engineering in Australia?
As the founder of Cloud Shuttle and DataEngBytes, I've had the privilege of observing the dynamic evolution of our data landscape. In this blog, I want to delve into the growing importance of data products for ANZ businesses and highlight how modern tools like Backstage, Mage, and Apache Iceberg are playing a pivotal role in this transformation.
The Evolution from Data Pipelines to Data Products
Gone are the days when data engineering was solely about constructing ETL pipelines. In our current data-centric environment, it's imperative to treat data as a product—delivering consistent value to consumers while upholding high standards of quality and reliability.
A recent report by McKinsey emphasises that organisations adopting a data-as-a-product mindset are 2.5 times more likely to excel in data-driven decision-making. This shift isn't merely a passing trend; it's a fundamental change in our approach to data engineering.
The Data Product Toolkit: Modern Solutions for Contemporary Challenges
Backstage: A Developer Portal for Data Teams
Originally developed by Spotify, Backstage has emerged as a robust platform for managing data products. It serves as a centralised hub, offering features such as:
- Centralised Documentation: Ensures all data assets are well-documented and easily accessible.
- Service Catalog: Provides a comprehensive overview of all services and tools in use.
- Template-Based Scaffolding: Streamlines the creation of new projects with standardised templates.
- Plugin Ecosystem: Supports a wide range of plugins to enhance functionality.
For instance, Toyota Motor North America combined Backstage with AWS to accelerate application deployment and achieved significant cost savings. Learn more about Toyota's implementation.
Mage: The Modern Data Pipeline Builder
At Cloud Shuttle, we've been particularly impressed with Mage's capabilities in the data engineering realm. This open-source tool offers:
- Visual Pipeline Building: Allows for intuitive construction of data workflows.
- Python-Native Development: Enables seamless integration with existing Python codebases.
- Built-In Testing and Debugging: Facilitates robust development and maintenance.
- Real-Time Collaboration: Supports team-based development with ease.
Mage's design philosophy emphasises flexibility and user-friendliness, making it a valuable asset for data teams. Explore Mage's features.
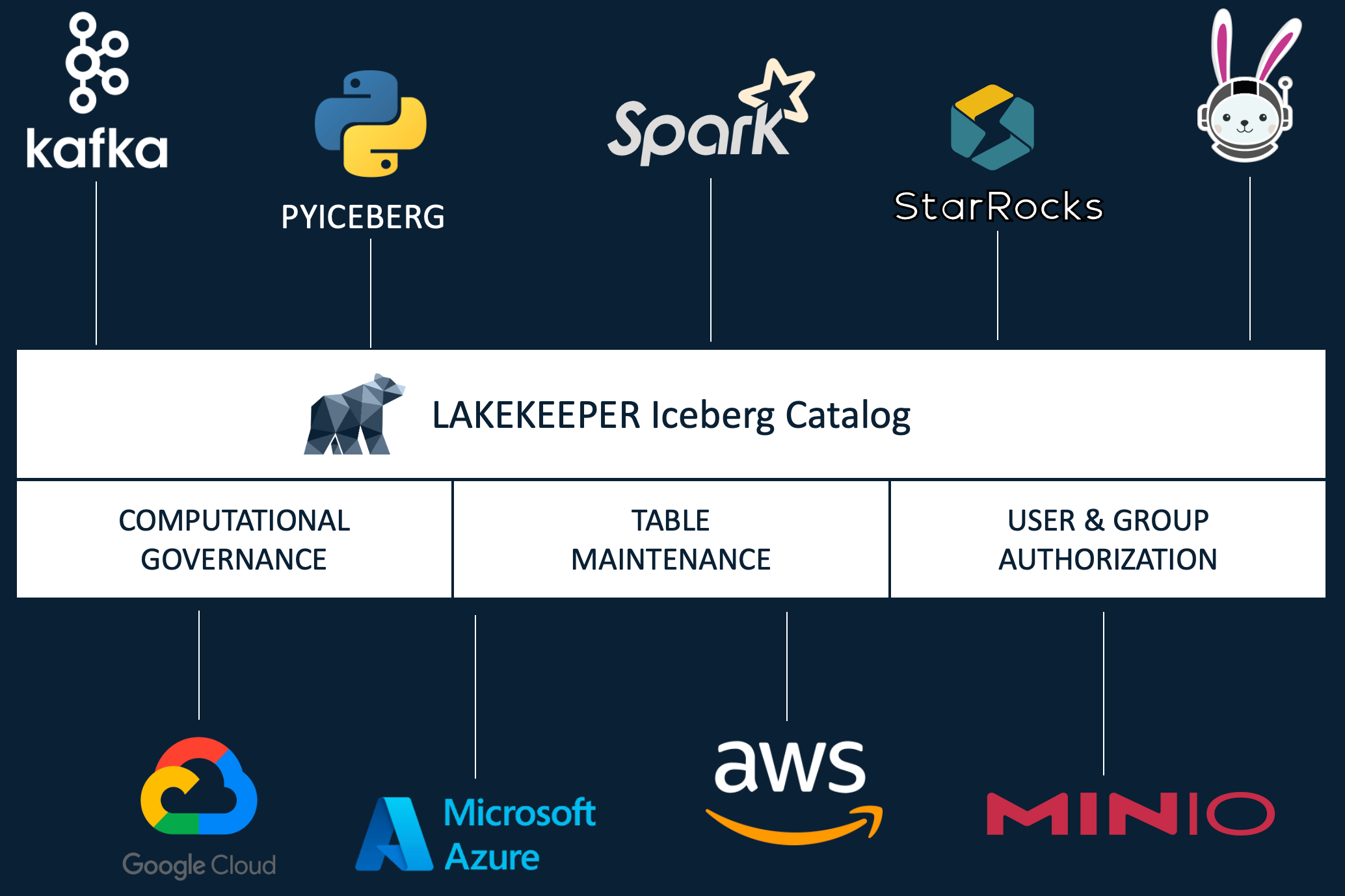
Apache Iceberg: Revolutionising Data Lakes
Apache Iceberg is transforming the management of large-scale data lakes. Initially developed at Netflix, it's now embraced by major organisations and rapidly growing startups worldwide. Key advantages include:
- Schema Evolution: Allows for seamless changes to data structures without disrupting operations.
- Time Travel Capabilities: Enables querying of historical data states.
- ACID Transactions: Ensures data integrity during concurrent operations.
- Enhanced Query Performance: Optimises data retrieval times.
In Australia, companies are integrating Apache Iceberg into their modern data architectures, leveraging its features to enhance data lake capabilities. Discover more about Apache Iceberg.
Real-world Impact in ANZ
Across Australia and New Zealand, various sectors are harnessing data products to drive innovation:
Financial Services
Leading banks are utilising data products to gain deeper customer insights and refine risk management strategies.
- Latitude Financial Services: By implementing a new machine learning propensity model, Latitude delivered personalised offers to customers with virtually no latency, resulting in a tenfold increase in the uptake of new products. Latitude Financial Services case study.
Mining
Resource companies are adopting data products to boost operational efficiency and safety.
- Newcrest Mining: Collaborating with Microsoft, Newcrest developed an intelligent IoT solution that provides greater insight, efficiency, and precision in managing mining operations. Newcrest Mining case study.
Retail
Top retailers are developing recommendation engines as data products to enhance customer engagement.
- Woolworths: Partnering with Tata Consultancy Services (TCS), Woolworths leveraged AI and machine learning to embrace data-driven retail, leading to improved decision-making and enhanced customer experiences. Woolworths case study.
These examples demonstrate how data products are transforming industries across the ANZ region, driving innovation and delivering tangible business benefits.
Embarking on the Data Product Journey
For Organisations aiming to modernise their data infrastrucutre, I recommend the following steps:
- Start Small: Identify a specific use case with clear value propositions.
- Prioritise Documentation: Utilise platforms like Backstage to maintain comprehensive and accessible documentation.
- Implement Quality Assurance: Establish checkpoints to ensure data quality throughout the pipeline.
- Design for Reusability: Develop modular components that can be repurposed across projects.
Looking Forward
The trajectory of data engineering in the ANZ region is promising. As more organisations transition to data product methodologies, we can anticipate:
- Elevated Data Quality: Consistent and reliable data outputs.
- Enhanced Team Collaboration: Improved synergy between cross-functional teams.
- Accelerated Time to Market: Faster deployment of data-driven solutions.
- Reduced Technical Debt: Streamlined systems with minimised legacy burdens.
At Cloud Shuttle, we're dedicated to guiding organisations through this transformative journey. Whether you're initiating your data product strategy or seeking to optimise existing frameworks, we're here to assist.
Book a free consultation here. To learn more about our services offering visit at Data Engineering Service | Cloud Shuttle.
Peter Hanssens is the founder of Cloud Shuttle and DataEngBytes, with over 15+ years of experience in data engineering. He is committed to helping organisations revolutionise their data operations through cutting-edge tools and best practices.
RELATED_NODES
NODE_CHAIN // SIG_FAST
NODE_01
Static egress IPs for Postgres on Fly.io: an Envoy egress proxy
Jun 8, 2026 · 06m read
NODE_02
AI Observability in Action: Cost Measurement & Evals with Bifrost, Langfuse, and Drover
Jun 5, 2026 · 06m read
NODE_03
Self-Governing Codebases: Bridging the Code-Architecture Gap with Governed RLMs
Jun 4, 2026 · 06m read
Cloud Shuttle Insights