
The AI Gateway ROI You Can Measure This Quarter
AI costs have a way of sneaking up on you. It starts small — a few API keys, some experimentation, a couple of features in production. Then the bill arrives and someone in finance asks why cloud spend went up 40% this quarter. Nobody has a clean answer.
Where the Costs Actually Are
- Prompt inefficiency — system prompts that are 3,000 tokens when 500 would do the same job, multiplied across millions of calls.
- Wrong model for the task — using a frontier model for simple classification that a smaller, cheaper model handles equally well.
- No caching — high-volume applications where the same queries are sent repeatedly at full token cost.
- No spending limits — individual teams with uncapped API keys, leading to surprise invoices at month end.
The Cost Optimisation Toolkit
Every incoming request passes through a simple decision tree before it ever reaches an LLM provider. The diagram below shows how the gateway classifies and routes — eliminating token spend where possible, and right-sizing model selection everywhere else.
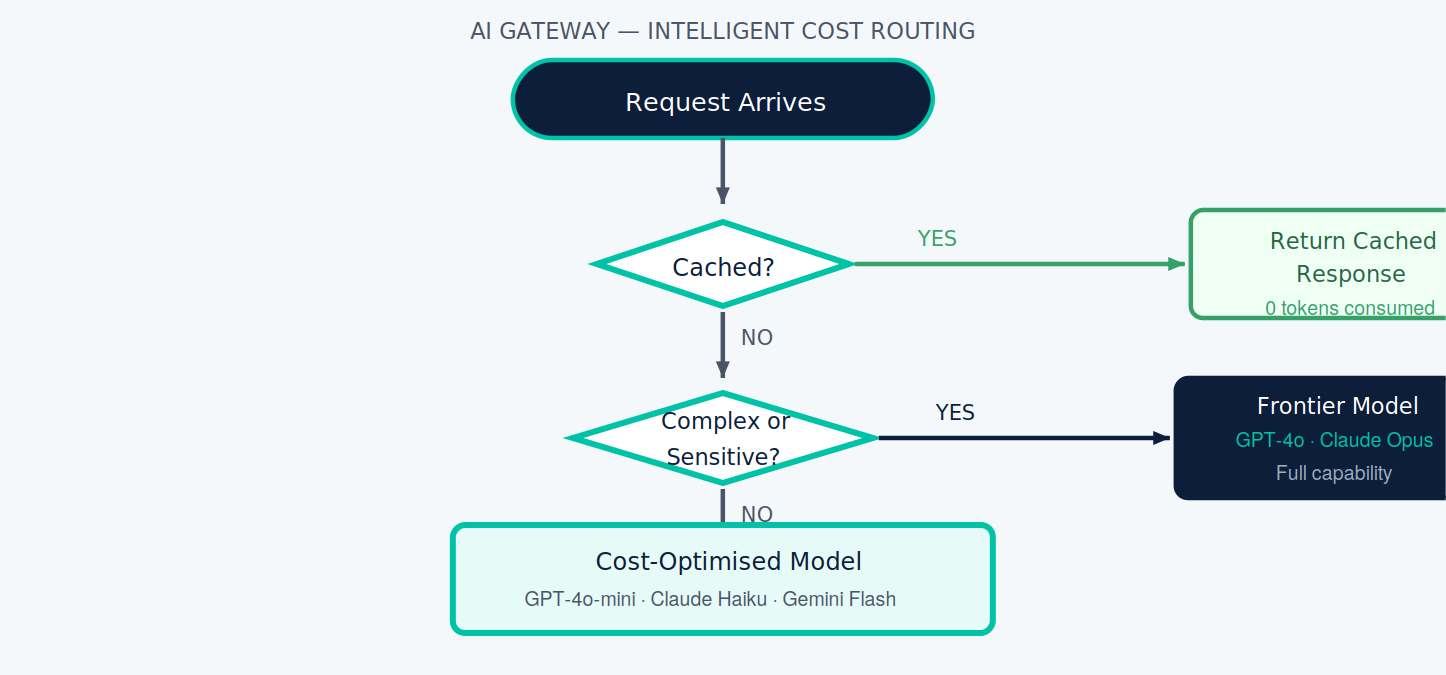
- Semantic caching — checks whether a semantically similar prompt has been answered recently. Cache hit rates of 20–40% are common.
- Intelligent routing — simple queries to cost-optimised models, complex reasoning to frontier models.
- Token budget enforcement — maximum token limits per request, per user, or per application.
- Usage alerting — real-time alerts when spending approaches thresholds, with team-level cost attribution.
Putting the Numbers Together
Conservative estimates for an organisation spending $10,000 AUD/month on LLM API costs.
- Semantic caching (25% hit rate) — $2,500/month
- Intelligent routing (30% queries downtiered) — $1,500–$3,000/month
- Prompt optimisation (15% token reduction) — $1,500/month
- Eliminating duplicate requests — $500–$1,000/month
- Total potential saving — $6,000–$8,000/month
In our experience, organisations with existing AI workloads recover the cost of an AI gateway within their first full billing cycle.
Performance and Reliability
- Load balancing across providers — if one endpoint is slow or unavailable, the gateway routes to another automatically.
- Automatic failover — if a provider returns an error, the gateway retries with a fallback. Your application logic doesn't handle this.
- Latency monitoring and SLAs — track Time-To-First-Token and end-to-end response times. Route to faster providers automatically when thresholds are breached.
Curious what your AI spend optimisation opportunity actually looks like?
Cloud Shuttle offers a no-obligation AI infrastructure review.
RELATED_NODES
NODE_CHAIN // SIG_FAST
NODE_01
Static egress IPs for Postgres on Fly.io: an Envoy egress proxy
Jun 8, 2026 · 06m read
NODE_02
AI Observability in Action: Cost Measurement & Evals with Bifrost, Langfuse, and Drover
Jun 5, 2026 · 06m read
NODE_03
Self-Governing Codebases: Bridging the Code-Architecture Gap with Governed RLMs
Jun 4, 2026 · 06m read
Cloud Shuttle Insights